Juval Lowy
2003년 8월
요약: 이 기사에서는 generics가 다루는 문제, generics의 구현 방법, 프로그래밍 모델의 이점, 제약 조건,
generic 메서드 및 위임, generic 상속 같은 고유하고 혁신적인 기능에 대해 논의합니다(41페이지/인쇄 페이지 기준).
GenericsInCSharp.msi
예제 파일을 다운로드하십시오.
참고 이 기사를 이해하려면 C# 1.1에 익숙해야 합니다. C# 언어에 대한
자세한 내용을 보려면 http://msdn.microsoft.com/vcsharp/language  를 방문하십시오.
를 방문하십시오.
목차
소개
generics 문제 정의
generics의 정의
generics 적용
generic 제약 조건
generics 및 캐스팅
상속 및 generics
generic 메서드
generic 위임
generics 및 반사
generics 및 .NET Framework
결론
소개
generics는 C# 2.0에서 가장 강력하고 기대되는 기능입니다. generics를 사용하면 실제 데이터 형식을 커밋하지 않고도 형식이
안전한 데이터 구조를 정의할 수 있습니다. 그러면 형식별 코드를 복제하지 않고도 데이터 처리 알고리즘을 다시 사용할 수 있기 때문에 성능이 크게
향상되고 코드의 품질이 높아집니다. 개념적으로 generics는 C++ 템플릿과 비슷하지만 구현 및 성능 면에서는 크게 다릅니다. 이 기사에서는
generics가 다루는 문제, generics의 구현 방법, 프로그래밍 모델의 이점, 제약 조건, generic 메서드 및 위임,
generic 상속 같은 고유하고 혁신적인 기능에 대해 논의합니다. 반사, 컬렉션, serialization, 원격 등 .NET
Framework의 다른 영역에서 generics를 활용하는 방법과 기본적으로 제공되는 기능을 향상시키는 방법에 대해서도 설명합니다.
generics 문제 정의
예를 들어 일반적인 Push() 및 Pop() 메서드를 제공하는 스택 같은 일상적인 데이터 구조가 있는 경우,
범용 스택을 개발할 때는 이를 사용하여 다양한 형식의 인스턴스를 저장할 수 있습니다. C# 1.1에서는 개체 기반 스택을 사용해야 합니다. 즉,
스택에 사용되는 내부 데이터 형식은 무정형 개체이며 스택 메서드는 개체와 상호 작용합니다.
public class Stack
{
object[] m_Items;
public void Push(object item)
{...}
public object Pop()
{...}
} (참고: 프로그래머 코멘트는 샘플 프로그램 파일에는 영문으로 제공되며 기사에는 설명을 위해 번역문으로 제공됩니다.)
코드 블록 1은 개체 기반 스택의 전체 구현을 보여 줍니다. 개체는 정식 .NET 기반 형식이므로 개체 기반 스택을 사용하여
정수 등 모든 형식의 항목을 보관할 수 있습니다.
Stack stack = new Stack();
stack.Push(1);
stack.Push(2);
int number = (int)stack.Pop();
코드 블록 1: 개체 기반 스택
public class Stack
{
readonly int m_Size;
int m_StackPointer = 0;
object[] m_Items;
public Stack():this(100)
{}
public Stack(int size)
{
m_Size = size;
m_Items = new object[m_Size];
}
public void Push(object item)
{
if(m_StackPointer >= m_Size)
throw new StackOverflowException();
m_Items[m_StackPointer] = item;
m_StackPointer++;
}
public object Pop()
{
m_StackPointer--;
if(m_StackPointer >= 0)
{
return m_Items[m_StackPointer];
}
else
{
m_StackPointer = 0;
throw new InvalidOperationException("Cannot pop an empty stack");
}
}
}
그러나 개체 기반 솔루션에는 두 가지 문제가 있습니다. 첫 번째 문제는 성능입니다. 값 형식을 사용할 경우 푸시하고 저장하려면 box하고,
스택에서 꺼내려면 unbox해야 합니다. boxing 및 unboxing은 그 자체만으로도 성능을 크게 저하시키지만 관리 힙의 부담도 늘어나므로
성능에 좋지 않은 영향을 미치는 가비지 수집이 증가하게 됩니다. 값 형식 대신 참조 형식을 사용하는 경우에도 개체에서 상호 작용하고 있는 실제
형식으로 캐스팅해야 하고 캐스팅에 따른 추가 작업이 필요하므로 성능이 여전히 저하됩니다.
Stack stack = new Stack();
stack.Push("1");
string number = (string)stack.Pop();
개체 기반 솔루션의 두 번째이자 더 심각한 문제는 형식의 안전성입니다. 컴파일러에서는 모든 내용을 개체로 캐스팅하거나 개체에서 캐스팅할 수
있으므로 컴파일 시 형식의 안전성이 낮아집니다. 예를 들어 다음 코드는 제대로 컴파일되지만 런타임에 잘못된 캐스트 예외가 발생합니다.
Stack stack = new Stack();
stack.Push(1);
//컴파일되지만 형식이 안전하지 않으며 예외를 throw합니다.
string number = (string)stack.Pop();
형식별, 즉 형식이 안전한 퍼포먼트 스택을 사용하여 이 두 가지 문제를 해결할 수 있습니다. 정수의 경우 IntStack을
구현하고 사용할 수 있습니다.
public class IntStack
{
int[] m_Items;
public void Push(int item){...}
public int Pop(){...}
}
IntStack stack = new IntStack();
stack.Push(1);
int number = stack.Pop();
문자열의 경우 StringStack을 구현합니다.
public class StringStack
{
string[] m_Items;
public void Push(string item){...}
public string Pop(){...}
}
StringStack stack = new StringStack();
stack.Push("1");
string number = stack.Pop();
나머지도 비슷합니다. 안타깝게도 이 방법으로 성능 및 형식 안전성 문제를 해결할 경우 이에 못지 않은 세 번째 문제, 즉 작업 생산성이
낮아지는 상황이 발생합니다. 형식별 데이터 구조를 작성하는 작업은 더디고 반복적이며 오류가 발생하기 쉽습니다. 데이터 구조에서 결함을 수정할
경우 한 곳에서만 해결하면 되는 것이 아니라 결과적으로는 동일한 데이터 구조인 형식별 중복 항목이 있는 곳마다 결함을 해결해야 합니다. 또한 알
수 없거나 아직 정의되지 않은 미래의 형식이 사용될지도 모르므로 개체 기반 데이터 구조도 유지해야 합니다. 따라서 대부분의 개발자는 형식별
데이터 구조가 실용적이지 못하다고 판단하여 결함이 있음에도 불구하고 개체 기반 데이터 구조를 사용합니다.
generics의 정의
generics를 사용하면 형식 안전성, 성능 또는 생산성을 그대로 유지하면서 형식이 안전한 클래스를 정의할 수 있습니다. 서버는 단 한
번만 generic 서버로 구현하게 되지만, 동시에 서버를 선언하여 어떤 형식에나 사용할 수 있습니다. 이를 위해 < 및
> 대괄호로 generic 형식 매개 변수를 둘러싸십시오. 예를 들어 다음과 같이 generic 스택을 정의하고
사용합니다.
public class Stack<T>
{
T[] m_Items;
public void Push(T item)
{...}
public T Pop()
{...}
}
Stack<int> stack = new Stack<int>();
stack.Push(1);
stack.Push(2);
int number = stack.Pop();
코드 블록 2는 generic 스택의 전체 구현을 보여 줍니다. 코드 블록 1과 코드 블록 2를
비교하여 코드 블록 1에서 사용된 모든 object가
코드 블록 2에서 T로 대체되었는지 확인하십시오.
generic 형식 매개 변수 T를 사용하여 Stack을 정의하는 것은 예외입니다.
public class Stack<T>
{...}
generic 스택을 사용할 경우 변수를 선언할 때와 인스턴스화할 때 모두 generic 형식 매개 변수 T 대신 사용할 형식을 컴파일러에
지정해야 합니다.
Stack<int> stack = new Stack<int>();
나머지는 컴파일러와 런타임에서 자동으로 수행합니다. T를 받아들이거나 반환하는 모든 메서드(속성)는 지정된 형식을 대신 사용하게 됩니다.
위 예제의 경우에는 정수를 사용합니다.
코드 블록 2. generic 스택
public class Stack<T>
{
readonly int m_Size;
int m_StackPointer = 0;
T[] m_Items;
public Stack():this(100)
{}
public Stack(int size)
{
m_Size = size;
m_Items = new T[m_Size];
}
public void Push(T item)
{
if(m_StackPointer >= m_Size)
throw new StackOverflowException();
m_Items[m_StackPointer] = item;
m_StackPointer++;
}
public T Pop()
{
m_StackPointer--;
if(m_StackPointer >= 0)
{
return m_Items[m_StackPointer];
}
else
{
m_StackPointer = 0;
throw new InvalidOperationException("Cannot pop an empty stack");
}
}
}
참고 T는 generic 형식이 Stack<T>일 경우의
generic 형식 매개 변수(형식 매개 변수)입니다.
이 프로그래밍 모델의 이점은 클라이언트가 서버 코드를 사용하는 방법에 따라 실제 데이터 형식은 변경될 수 있지만 내부 알고리즘과 데이터
조작은 그대로 유지된다는 것입니다.
generics 구현
표면적으로 C# generics는 C++ 템플릿과 매우 유사하지만 컴파일러에서 구현되고 지원되는 방법에는 중요한 차이점이 있습니다. 이
기사의 뒷부분에 나와 있듯이 둘 사이의 차이점은 generics를 사용하는 방법에 큰 영향을 미칩니다. C++ 템플릿과 비교하여 C#
generics는 좀 더 안전하지만 기능이 다소 제한되어 있습니다.
C++에서 템플릿은 사실 매크로일 뿐이며 컴파일된 이진수로 유지되지 않습니다. 특정 형식의 템플릿 클래스를 사용하지 않으면 컴파일러가
템플릿 코드를 컴파일할 수도 없습니다. 형식을 지정하면 컴파일러가 코드를 인라인에 삽입하여 generic 형식 매개 변수의 모든 항목을 지정된
형식으로 바꿉니다. 템플릿 클래스에서 발생한 컴파일 오류는 템플릿 클래스를 사용할 때만 발견할 수 있습니다. 또한 특정 형식을 사용할 때마다
컴파일러는 사용자가 이미 응용 프로그램의 다른 곳에서 템플릿 클래스에 대해 해당 형식을 지정했는지에 관계없이 형식별 코드를 삽입합니다. 따라서
코드가 비대해져 로드 시간이 길어질 뿐 아니라 메모리 공간도 많이 차지하게 됩니다.
.NET 2.0에서는 generics가 IL(Intermediate Language) 및 CLR 자체를 기본적으로 지원합니다.
generic C# 서버 쪽 코드를 컴파일하면 컴파일러가 이를 다른 모든 형식과 마찬가지로 IL로 컴파일합니다. 그러나 IL에는 실제 특정
형식의 매개 변수나 자리 표시자만 들어 있습니다. 또한 generic 서버의 메타데이터에는 generic 정보가 들어 있습니다.
클라이언트 쪽 컴파일러는 해당 generic 메타데이터를 사용하여 형식의 안전성을 지원합니다. 클라이언트가 generic 형식 매개 변수
대신 특정 형식을 제공하는 경우 클라이언트의 컴파일러는 서버 메타데이터에 있는 generic 형식 매개 변수를 지정된 형식으로 대체합니다.
그러면 generics가 전혀 사용되지 않은 것처럼 클라이언트의 컴파일러에 서버의 형식별 정의가 제공됩니다. 이러한 방법으로 클라이언트
컴파일러는 올바른 메서드 매개 변수, 형식 안전성 검사 및 형식별 IntelliSense®도 적용할 수 있습니다.
흥미로운 점은 .NET이 서버의 generic IL을 기계어 코드로 컴파일하는 방식입니다. 사실, 실제로 만들어지는 기계어 코드는 지정된
형식이 값 형식인지 아니면 참조 형식인지에 따라 달라집니다. 클라이언트가 값 형식을 지정하면 JIT 컴파일러가 IL에 있는 generic 형식
매개 변수를 특정 값 형식으로 바꾸고 네이티브 코드로 컴파일합니다. 그러나 JIT 컴파일러는 이미 생성한 형식별 서버 코드를 추적합니다. 이미
기계어 코드로 컴파일한 값 형식을 사용하여 generic 서버를 컴파일하도록 JIT 컴파일러에 지정하는 경우 해당 서버 코드에 대한 참조만
반환됩니다. JIT 컴파일러는 차후의 모든 항목에서 동일한 값 형식별 서버 코드를 사용하므로 코드가 비대해지지 않습니다.
클라이언트가 참조 형식을 지정하면 JIT 컴파일러가 서버 IL에 있는 generic 매개 변수를 개체로 바꾸고 네이티브 코드로
컴파일합니다. 해당 코드는 차후의 모든 참조 형식 요청에서 generic 형식 매개 변수 대신 사용됩니다. 이러한 방법으로 JIT 컴파일러는
실제 코드만 다시 사용합니다. 인스턴스는 여전히 크기에 따라 관리 힙에 할당되며 캐스팅은 없습니다.
generics 이점
.NET에서는 generics를 구현할 때 사용한 코드와 작업을 generics를 사용할 때 다시 사용할 수 있습니다. 값 형식을
사용하거나 참조 형식을 사용하거나에 관계없이 코드를 비대하게 만들지 않고도 형식 및 내부 데이터를 변경할 수 있습니다. 코드를 한 번 개발하고
테스트하고 배포한 후에는 모든 컴파일러 지원과 형식 안전성이 보장되는 상태에서 미래의 형식을 포함한 모든 형식에 다시 사용할 수 있습니다.
generic 코드를 사용하면 값 형식을 boxing 및 unboxing하거나 참조 형식을 다운 캐스팅하지 않아도 되므로 성능이 크게
향상됩니다. 값 형식을 사용하면 형식에 액세스할 때 일반적으로 성능이 200% 향상되며, 참조 형식을 사용하면 100%의 성능 향상을 기대할 수
있습니다. 물론 전체 응용 프로그램의 성능은 향상될 수도 있고 그렇지 않을 수도 있습니다. 이 기사에서 사용한 소스 코드에는 간단한 루프에서
스택을 실행하는 마이크로 벤치마크 응용 프로그램이 포함되어 있습니다. 이 응용 프로그램을 사용하면 개체 기반 스택과 generic 스택에서 값
형식 및 참조 형식을 사용해 볼 수 있으며 루프 반복의 수를 변경하여 generics가 성능에 미치는 영향을 확인할 수도 있습니다.
generics 적용
IL 및 CLR에서 generics를 기본적으로 지원하므로 대부분의 CLR 호환 언어는 generic 형식을 활용할 수 있습니다. 예를
들어 다음은 코드 블록 2의 generic 스택을 사용하는 몇 가지 Visual Basic® .NET 코드입니다.
Dim stack As Stack(Of Integer)
stack = new Stack(Of Integer)
stack.Push(3)
Dim number As Integer
number = stack.Pop()
클래스 및 구조체에서 generics를 사용할 수 있습니다. 다음은 유용한 generic point 구조체입니다.
public struct Point<T>
{
public T X;
public T Y;
}
예를 들어 generic point를 정수 좌표에 사용할 수 있습니다.
Point<int> point;
point.X = 1;
point.Y = 2;
또는 부동 소수점 정밀도가 필요한 차트 좌표에 사용할 수 있습니다.
Point<double> point;
point.X = 1.2;
point.Y = 3.4;
지금까지 소개한 기본적인 generics 구문 이외에도 C# 2.0은 generics를 사용할 때 일부 C# 1.1 구문을 오버로드하여
특수화합니다. 코드 블록 2의 Pop() 메서드를 예로 들어 보겠습니다. 스택이 비어 있을 때 예외를 throw하는
대신 스택에 저장된 형식의 기본값을 반환할 수 있습니다. 개체 기반 스택을 사용하는 경우 null만 반환하면 되지만 generic 스택이 값
형식과 함께 사용될 수도 있습니다. 이 문제를 해결하기 위해 모든 generic 형식 매개 변수는 형식의 기본값을 반환하는
default라는 속성을 지원합니다.
다음은 Pop() 메서드 구현에서 기본값을 사용하는 방법입니다.
public T Pop()
{
m_StackPointer--;
if(m_StackPointer >= 0)
{
return m_Items[m_StackPointer];
}
else
{
m_StackPointer = 0;
return T.default;
}
}
참조 형식의 기본값은 null이고 정수, 열거 및 구조 같은 값 형식의 기본값은 구조를 0으로 채우는 제로 화이트워시입니다. 따라서 스택이
문자열로 구성되어 있으면 스택이 비어 있을 때 Pop() 메서드가 null을 반환하고, 스택이 정수로 구성되어 있으면 스택이 비어
있을 때 Pop() 메서드가 0을 반환합니다.
복수 generic 형식
단일 형식은 복수 generic 형식 매개 변수를 정의할 수 있습니다. 코드 블록 3에 나와 있는 generic 연결 리스트를
예로 들어 보겠습니다.
코드 블록 3. generic 연결 리스트
class Node<K,T>
{
public Node()
{
Key = K.default;
Item = T.default;
licenseStream = null;
}
public Node(K key,T item,Node<K,T> nextNode)
{
Key = key;
Item = item;
NextNode = nextNode;
}
public K Key;
public T Item;
public Node<K,T> NextNode;
}
public class LinkedList<K,T>
{
public LinkedList()
{
m_Head = new Node<K,T>();
}
public void AddHead(K key,T item)
{
Node<K,T> newNode = new Node<K,T>(key,item,m_Head.NextNode);
m_Head.NextNode = newNode;
}
Node<K,T> m_Head;
}
연결 리스트에는 노드가 저장됩니다.
class Node<K,T>
{...}
각 노드에는 generic 형식 매개 변수 K의 키와 generic 형식 매개 변수 T의 값이 들어 있습니다. 리스트에 있는 다음 노드에
대한 참조도 들어 있습니다. 연결 리스트 자체는 generic 형식 매개 변수 K 및 T에 의해 정의됩니다.
public class LinkedList<K,T>
{...}
이로 인해 리스트는 AddHead() 같은 generic 메서드를 노출할 수 있습니다.
public void AddHead(K key,T item);
generics를 사용하는 형식의 변수를 선언할 때마다 사용할 형식을 지정해야 합니다. 그러나 지정된 형식 자체가 generic 형식일
수도 있습니다. 예를 들어 연결 리스트에 노드 형식의 m_Head라는 멤버 변수가 있으며 리스트에 있는 첫 번째 항목을 참조하는 데 사용됩니다.
m_Head는 리스트의 자체 generic 형식 매개 변수 K 및 T를 사용하여 선언됩니다.
Node<K,T> m_Head;
노드를 인스턴스화할 때 특정 형식을 제공해야 하며 다시 한 번 연결 리스트의 자체 generic 형식 매개 변수를 사용할 수
있습니다.
public void AddHead(K key,T item)
{
Node<K,T> newNode = new Node<K,T>(key,item,m_Head.NextNode);
m_Head.NextNode = newNode;
}
이 리스트에서 generic 형식 매개 변수의 노드와 동일한 이름을 사용한 것은 단지 이해를 돕기 위함입니다. 다음과 같이 다른 이름을
사용할 수도 있습니다.
public class LinkedList<U,V>
{...}
또는
public class LinkedList<KeyType,DataType>
{...}
이 경우 m_Head는 다음과 같이 선언됩니다.
Node<KeyType,DataType> m_Head;
연결 리스트를 사용 중인 클라이언트는 특정 형식을 제공해야 합니다. 클라이언트는 정수를 키로, 문자열을 데이터 항목으로 선택할 수
있습니다.
LinkedList<int,string> list = new LinkedList<int,string>();
list.AddHead(123,"AAA");
그러나 클라이언트가 키의 타임스탬프 같은 다른 조합을 선택할 수도 있습니다.
LinkedList<DateTime,string> list = new LinkedList<DateTime,string>();
list.AddHead(DateTime.Now,"AAA");
때로는 특정 형식의 특정 조합에 별칭을 지정하는 것이 좋습니다. 코드 블록 4에 나와 있는 것처럼 using 문을 사용하면
됩니다. 별칭 지정의 범위는 파일의 범위이므로 using 네임스페이스를 사용할 때와 같은 방법으로 프로젝트 파일 전체에서 별칭 지정을 반복해야
합니다.
코드 블록 4. generic 형식 별칭 지정
using List = LinkedList<int,string>;
class ListClient
{
static void Main(string[] args)
{
List list = new List();
list.AddHead(123,"AAA");
}
}
generic 제약 조건
특정 형식이 제공되어야 컴파일러가 템플릿 코드를 컴파일하는 C++에서와 달리 C# generics에서는 클라이언트가 사용할 특정 형식에
관계없이 컴파일러가 generic 코드를 IL로 컴파일합니다. 따라서 generic 코드는 클라이언트가 사용하는 특정 형식과 호환되지 않는
generic 형식 매개 변수의 메서드, 속성 또는 멤버를 사용하려고 할 수 있습니다. 이는 결과적으로 형식 안전성을 떨어뜨리기 때문에 허용되지
않습니다. C#에서는 클라이언트가 지정한 형식이 준수해야 하는 제약 조건을 컴파일러에 지정하여 generic 형식 매개 변수 대신 사용되도록
해야 합니다. 두 가지 유형의 제약 조건이 있습니다. 파생 제약 조건은 generic 형식 매개 변수가 인터페이스 또는 특정 기본 클래스 같은
기본 형식에서 파생된다는 것을 컴파일러에 알립니다. 기본 생성자 제약 조건은 generic 형식 매개 변수가 기본 public 생성자(매개
변수가 없는 public 생성자)를 노출한다는 것을 컴파일러에 알립니다. generic 형식에는 여러 제약 조건이 있을 수 있으며 기본
형식으로부터 메서드 또는 멤버를 제안하는 것과 같이 generic 형식 매개 변수를 사용할 때 제약 조건을 반영하는 IntelliSense도
있습니다.
제약 조건은 선택적이지만 generic 형식을 개발할 때 필수적인 경우가 종종 있습니다. 제약 조건이 없으면 컴파일러가 좀 더 신중하고
형식이 안전한 접근 방식을 사용하며 generic 형식 매개 변수에서 개체 수준 기능만 사용할 수 있도록 합니다. 제약 조건은 generic
형식 메타데이터의 일부분이므로 클라이언트 쪽 컴파일러도 제약 조건을 활용할 수 있습니다. 클라이언트 쪽 컴파일러를 사용하는 클라이언트 개발자는
제약 조건을 준수하는 형식만을 사용할 수 있으므로 형식 안전성이 보장됩니다.
긴 예를 들어 제약 조건의 필요성과 사용 방법을 설명해 보겠습니다. 코드 블록 3의 연결 리스트에 인덱싱 기능 또는 키 기준
검색 기능을 추가하려고 합니다.
public class LinkedList<K,T>
{
T Find(K key)
{...}
public T this[K key]
{
get{return Find(key);}
}
}
그러면 클라이언트가 다음 코드를 작성할 수 있습니다.
LinkedList<int,string> list = new LinkedList<int,string>();
list.AddHead(123,"AAA");
list.AddHead(456,"BBB");
string item = list[456];
Debug.Assert(item == "BBB");
검색 기능을 구현하려면 리스트를 검사하고, 각 노드의 키를 검색 중인 키와 비교하고, 키가 일치하는 노드의 항목을 반환해야 합니다. 문제는
다음 Find() 구현이 컴파일되지 않는다는 것입니다.
T Find(K key)
{
Node<K,T> current = m_Head;
while(current.NextNode != null)
{
if(current.Key == key) //컴파일되지 않습니다.
break;
else
current = current.NextNode;
}
return current.Item;
}
그 이유는 컴파일러가 다음 줄의 컴파일을 거부하기 때문입니다.
if(current.Key == key)
컴파일러는 K(클라이언트가 제공하는 실제 형식)가 == 연산자를 지원하는지 알지 못하므로 위 줄은 컴파일되지 않습니다. 예를 들어 구조체는
기본적으로 이러한 구현을 제공하지 않습니다. IComparable 인터페이스를 사용하여 == 연산자 문제를 해결할 수
있습니다.
public interface IComparable
{
int CompareTo(object obj);
}
CompareTo()는 비교한 개체가 인터페이스를 구현 중인 개체와 일치할 경우 0을 반환하므로 Find()
메서드에서 다음과 같이 사용할 수 있습니다.
if(current.Key.CompareTo(key) == 0)
안타깝게도 K(클라이언트가 제공하는 실제 형식)가 IComparable에서 파생되었다는 것을 컴파일러가 알 수 있는 방법이
없으므로 이 줄도 컴파일되지 않습니다.
IComparable에 명시적으로 캐스팅하여 컴파일러가 비교 줄을 컴파일하도록 할 수도 있지만 그럴 경우에는 형식 안전성이
낮아지는 것을 감수해야 합니다.
if(((IComparable)(current.Key)).CompareTo(key) == 0)
클라이언트가 사용하는 형식이 IComparable에서 파생되지 않으면 런타임 예외가 발생합니다. 또한 사용된 키 형식이 키
형식 매개 변수가 아니라 값 형식이면 키의 boxing을 강요하는 것이므로 성능에 다소 영향을 미칠 수 있습니다.
파생 제약 조건
C# 2.0에서는 예약된 키워드 where를 사용하여 제약 조건을 정의합니다. generic 형식 매개 변수에서 뒤에 파생
콜론이 붙은 where 키워드를 사용하여 generic 형식 매개 변수가 특정 인터페이스를 구현한다는 것을 컴파일러에 알립니다.
예를 들어 다음은 LinkedList의 Find() 메서드를 구현하는 데 필요한 파생 제약 조건입니다.
public class LinkedList<K,T> where K : IComparable
{
T Find(K key)
{
Node<K,T> current = m_Head;
while(current.NextNode != null)
{
if(current.Key.CompareTo(key) == 0)
break;
else
current = current.NextNode;
}
return current.Item;
}
//구현의 나머지 부분
}
제약 조건에서 IComparable을 사용할 수는 있지만 사용된 키가 정수 같은 값 형식일 경우에는 boxing으로 인해
여전히 성능이 저하됩니다. 이를 해결하기 위해 System.Collections.Generics 네임스페이스는 generic 인터페이스
IComparable<T>를 정의합니다.
public interface IComparable<T>
{
int CompareTo(T other);
}
키의 형식을 형식 매개 변수로 사용하여 키 형식 매개 변수가 IComparable<T>를 지원하도록 제한할 수
있습니다. 이 경우 형식 안전성이 보장될 뿐만 아니라 키로 사용될 때 값 형식을 boxing할 필요도 없습니다.
public class LinkedList<K,T> where K : IComparable<K>
{...}
사실 .NET 1.1에서 IComparable을 지원하던 형식은 모두 .NET 2.0에서
IComparable<T>를 지원합니다. 따라서 int, string, Guid, DateTime 등 일반 형식의 키를
사용할 수 있습니다.
C# 2.0에서는 모든 제약 조건이 generic 클래스의 실제 파생 목록 뒤에 와야 합니다. 예를 들어 LinkedList가
IEnumerable<T> 인터페이스(iterator 지원)에서 파생된 경우 where 키워드를 바로 뒤에
넣습니다.
public class LinkedList<K,T> : IEnumerable<T> where K : IComparable<K>
{...}
제약 조건은 LinkedList 클래스의 선언 줄에서 generic 형식 매개 변수 K가 정의되는 위치에 나타납니다. 이로
인해 LinkedList 클래스는 K를 형식 매개 변수로 사용하여 IComparable<T>를 구현하는
것처럼 generic 형식 매개 변수 K를 처리할 수 있습니다. 제한하는 인터페이스의 메서드에 대한 IntelliSense 지원도 받습니다.
리스트의 키에 대한 구체적인 형식을 제공하는 LinkedList 형식의 변수를 클라이언트가 선언할 때 클라이언트 쪽 컴파일러는
키 형식이 IComparable<T>(키의 형식을 형식 매개 변수로 사용)에서 파생되도록 요구합니다. 그렇지 않은
경우에는 클라이언트 코드 작성을 거부합니다.
일반적으로는 필요한 수준에서만 제약 조건을 정의해야 합니다. 연결 리스트 예제에서 노드 자체는 키를 비교하지 않기 때문에 노드 수준에서
IComparable<T> 파생 제약 조건을 정의하는 것은 아무런 의미가 없습니다. 노드 수준에서 파생 제약 조건을
정의한 경우 리스트가 키를 비교하지 않는다고 해도 LinkedList 수준에서도 제약 조건을 넣어야 합니다. 리스트에 노드가 멤버
변수로 포함되어 있어서 컴파일러는 노드가 generic 키 형식에 넣은 제약 조건을 리스트 수준에서 정의된 키 형식이 준수하도록 요구하기
때문입니다.
다시 말해, 노드를 다음과 같이 정의합니다.
class Node<K,T> where K : IComparable<K>
{...}
이 경우 리스트 수준에 대해 Find() 메서드나 기타 메서드를 제공하지 않더라도 리스트 수준에서 제약 조건을 반복해야
합니다.
public class LinkedList<KeyType,DataType> where KeyType : IComparable<KeyType>
{
Node<KeyType,DataType> m_Head;
}
같은 generic 형식 매개 변수에 있는 여러 인터페이스를 쉼표로 구분하여 제한할 수 있습니다. 다음 예를 살펴봅시다.
public class LinkedList<K,T> where K : IComparable<K>,IConvertible
{...}
예를 들어 클래스가 사용하는 모든 generic 형식 매개 변수에 대한 제약 조건을 제공할 수 있습니다.
public class LinkedList<K,T> where K : IComparable<K>
where T : ICloneable
{...}
generic 형식 매개 변수가 특정 기본 클래스에서 파생되는 것을 의미하며 이를 규정하는 기본 클래스 제약 조건을 사용할 수
있습니다.
public class MyBaseClass
{...}
public class LinkedList<K,T> where K : MyBaseClass
{...}
그러나 C#는 구현의 복수 상속을 지원하지 않기 때문에 제약 조건에서는 기본 클래스를 하나만 사용할 수 있습니다. 당연히 제한한 기본
클래스는 봉인(sealed) 클래스가 될 수 없으므로 컴파일러가 기본 클래스를 적용합니다. 또한 System.Delegate 또는
System.Array를 기본 클래스로 제한할 수 없습니다.
기본 클래스와 하나 이상의 인터페이스를 모두 제한할 수 있지만 파생 제약 조건 목록에서 기본 클래스가 먼저 나와야 합니다.
public class LinkedList<K,T> where K : MyBaseClass, IComparable<K>
{...}
C#에서는 naked generic 형식 매개 변수를 제약 조건으로 지정할 수 없습니다.
public class LinkedList<K,T,U> where K : U //컴파일되지 않습니다.
{...}
그러나 C#에서 다른 generic 형식을 제약 조건으로 사용할 수는 있습니다.
public interface ISomeInterface<T>
{...}
public class LinkedList<K,T> where K : ISomeInterface<int>
{...}
다른 generic 형식을 기본 형식으로 제한하는 경우 사용자 고유의 형식 매개 변수에 대한 generic 형식 매개 변수를 지정하여 해당
형식 generic을 유지할 수 있습니다. 예를 들어 generic 인터페이스 제약 조건의 경우는 다음과 같습니다.
public class LinkedList<K,T> where K : ISomeInterface<T>
{...}
generic 기본 클래스 제약 조건의 경우는 다음과 같습니다.
public class MySubClass<T> where T : MyBaseClass<T>
{...}
마지막으로 파생 제약 조건을 제공하는 경우 제한하는 기본 형식(인터페이스 또는 기본 클래스)은 정의하는 generic 형식 매개 변수와
일관되게 표시되어야 합니다. 예를 들어 다음 제약 조건은 internal 형식이 public 형식을 사용할 수 있기 때문에 유효합니다.
public class MyBaseClass
{}
internal class MySubClass<T> where T : MyBaseClass
{}
그러나 다음과 같이 두 클래스의 표시 순서가 바뀐 경우는 다릅니다.
internal class MyBaseClass
{}
public class MySubClass<T> where T : MyBaseClass
{}
이 경우 public 형식 대신 internal 형식으로 적용된 MySubClass를 렌더링하면서 generic 형식
MySubClass를 사용할 수 있는 어셈블리 외부의 클라이언트가 없기 때문에 컴파일러에서 오류가 발생합니다. 외부 클라이언트가
MySubClass를 사용할 수 없는 이유는 MySubClass 형식의 변수를 선언하려면 internal 형식
MyBaseClass에서 파생되는 형식을 사용해야 하기 때문입니다.
생성자 제약 조건
generic 클래스 내에서 새 generic 개체를 인스턴스화하려고 합니다. 이 경우 문제는 클라이언트가 사용할 특정 형식에 일치하는
생성자가 있는지 C# 컴파일러가 알지 못하므로 인스턴스화 줄의 컴파일을 거부한다는 것입니다.
이 문제를 해결하기 위해 C#에서는 generic 형식 매개 변수가 public 기본 생성자를 반드시 지원하도록 제한할 수 있습니다.
new() 제약 조건을 사용하면 됩니다. 예를 들어 다음은 코드 블록 3에서 generic Node
<K,T>의 기본 생성자를 구현하는 여러 가지 방법입니다.
class Node<K,T> where T : new()
{
public Node()
{
Key = K.default;
Item = new T();
licenseStream = null;
}
public K Key;
public T Item;
public Node<K,T> NextNode;
}
생성자 제약 조건을 파생 제약 조건과 결합할 수 있습니다. 단, 제약 조건 목록에서 생성자 제약 조건이 마지막에 나와야 합니다.
public class LinkedList<K,T> where K : IComparable<K>,new()
{...}
generics 및 캐스팅
코드 블록 5에 나와 있듯이 C# 컴파일러에서는 generic 형식 매개 변수를 개체 또는 제약 조건이 지정된 형식에만
암시적으로 캐스팅할 수 있습니다. 이와 같이 암시적으로 캐스팅하면 컴파일할 때 비호환성을 모두 찾을 수 있으므로 형식상 안전합니다.
코드 블록 5. generic 형식 매개 변수의 암시적 캐스팅
interface ISomeInterface
{...}
class BaseClass
{...}
class MyClass<T> where T : BaseClass,ISomeInterface
{
void SomeMethod(T t)
{
ISomeInterface obj1 = t;
BaseClass obj2 = t;
object obj3 = t;
}
}
컴파일러에서 generic 형식 매개 변수를 다른 모든 인터페이스에 명시적으로 캐스팅할 수 있지만 클래스에는 명시적으로 캐스팅할 수
없습니다.
interface ISomeInterface
{...}
class SomeClass
{...}
class MyClass<T>
{
void SomeMethod(T t)
{
ISomeInterface obj1 = (ISomeInterface)t;//컴파일됩니다.
SomeClass obj2 = (SomeClass)t; //컴파일되지 않습니다.
}
}
그러나 임시 Object 변수를 사용하여 강제로 generic 형식 매개 변수에서 다른 형식으로 캐스팅되도록 할 수 있습니다.
class SomeClass
{...}
class MyClass<T>
{
void SomeMethod(T t)
{
object temp = t;
SomeClass obj = (SomeClass)temp;
}
}
물론, generic 형식 매개 변수 대신 사용된 구체적인 형식이 명시적으로 캐스팅하는 형식에서 파생되지 않는 경우에는 런타임에 예외가
throw될 수 있으므로 이러한 명시적 캐스팅에는 위험이 따릅니다. 예외가 발생할 위험이 있는 캐스팅을 수행하는 대신 코드 블록
6에서와 같이 is 및 as 연산자를 사용하는 것이 더 나은 방법입니다. is 연산자는 generic 형식 매개 변수가 쿼리한 형식의 것일 경우
true를 반환하며, as는 형식이 호환되면 캐스트를 수행하고
호환되지 않으면 null을 반환합니다. is 및 as는 naked generic 형식 매개 변수와 특정 매개 변수가 있는
generic 클래스에서 모두 사용할 수 있습니다.
코드 블록 6. generic 형식 매개 변수에서 'is' 및 'as' 연산자 사용
public class MyClass<T>
{
public void SomeMethod(T t)
{
if(t is int)
{...}
if(t is LinkedList<int,string>)
{...}
string str = t as string;
if (drv != null)
{...}
LinkedList<int,string> list = t as LinkedList<int,string>;
if(list != null)
{...}
}
}
상속 및 generics
generic 기본 클래스로부터 파생할 경우 기본 클래스의 generic 형식 매개 변수 대신 특정 형식을 제공해야 합니다.
public class BaseClass<T>
{...}
public class SubClass : BaseClass<int>
{...}
하위 클래스가 구체적인 형식이 아니라 generic인 경우 subclass generic 형식 매개 변수를 generic 기본 클래스의
지정된 형식으로 사용할 수 있습니다.
public class SubClass<T> : BaseClass<T>
{...}
subclass generic 형식 매개 변수를 사용할 때는 하위 클래스 수준의 기본 클래스 수준에서 규정된 모든 제약 조건을 반복해야
합니다. 예를 들어 파생 제약 조건은 다음과 같습니다.
public class BaseClass<T> where T : ISomeInterface
{...}
public class SubClass<T> : BaseClass<T> where T : ISomeInterface
{...}
생성자 제약 조건은 다음과 같습니다.
public class BaseClass<T> where T : new()
{
public T SomeMethod()
{
return new T();
}
}
public class SubClass<T> : BaseClass<T> where T : new()
{...}
기본 클래스는 서명이 generic 형식 매개 변수를 사용하는 가상 메서드를 정의할 수 있습니다. 가상 메서드를 다시 정의할 경우 하위
클래스는 메서드 서명에서 해당 형식을 제공해야 합니다.
public class BaseClass<T>
{
public virtual T SomeMethod()
{...}
}
public class SubClass: BaseClass<int>
{
public override int SomeMethod()
{...}
}
하위 클래스가 generic이면 자체 generic 형식 매개 변수를 사용하여 다시 정의할 수도 있습니다.
public class SubClass<T>: BaseClass<T>
{
public override T SomeMethod()
{...}
}
generic 인터페이스, generic 추상 클래스 및 generic 추상 메서드도 정의할 수 있습니다. 이러한 형식은 다른
generic 기본 형식과 마찬가지로 동작합니다.
public interface ISomeInterface<T>
{
T SomeMethod(T t);
}
public abstract class BaseClass<T>
{
public abstract T SomeMethod(T t);
}
public class SubClass<T> : BaseClass<T>
{
public override T SomeMethod(T t)
{...)
}
generic 추상 메서드 및 generic 인터페이스의 흥미로운 사용 방법이 있습니다. C# 2.0에서는 generic 형식 매개 변수에
+ 또는 += 같은 연산자를 사용할 수 없습니다. 예를 들어 C# 2.0에는 연산자 제약 조건이 없기 때문에 다음 코드는 컴파일되지
않습니다.
public class Calculator<T>
{
public T Add(T arg1,T arg2)
{
return arg1 + arg2;//컴파일되지 않습니다.
}
//메서드의 나머지 부분
}
그러나 이 문제는 generic 연산을 정의하여 추상 메서드 또는 추상 인터페이스(선호됨)를 사용함으로써 보완할 수 있습니다. 추상
메서드에는 코드가 있을 수 없으므로 기본 클래스 수준에서 generic 연산을 지정하고 하위 클래스 수준에서 구체적인 형식 및 구현을 제공하면
됩니다.
public abstract class BaseCalculator<T>
{
public abstract T Add(T arg1,T arg2);
public abstract T Subtract(T arg1,T arg2);
public abstract T Divide(T arg1,T arg2);
public abstract T Multiply(T arg1,T arg2);
}
public class MyCalculator : BaseCalculator<int>
{
public override int Add(int arg1, int arg2)
{
return arg1 + arg2;
}
//메서드의 나머지 부분
}
generic 인터페이스는 좀 더 나은 솔루션을 제공합니다.
public interface ICalculator<T>
{
T Add(T arg1,T arg2);
//메서드의 나머지 부분
}
public class MyCalculator : ICalculator<int>
{
public int Add(int arg1, int arg2)
{
return arg1 + arg2;
}
//메서드의 나머지 부분
}
generic 메서드
C# 2.0에서 메서드는 해당 실행 범위에 고유한 generic 형식 매개 변수를 정의할 수 있습니다.
public class MyClass<T>
{
public void MyMethod<X>(X x)
{...}
}
이는 매번 다른 형식으로 메서드를 호출할 수 있도록 하는 중요한 기능으로, 유틸리티 클래스에 특히 편리합니다.
포함하는 클래스가 generics를 전혀 사용하지 않는 경우에도 메서드별 generic 형식 매개 변수를 정의할 수 있습니다.
public class MyClass
{
public void MyMethod<T>(T t)
{...}
}
이 기능은 메서드 전용입니다. 속성이나 인덱서는 클래스 범위에 정의된 generic 형식 매개 변수만 사용할 수 있습니다.
generic 형식 매개 변수를 정의하는 메서드를 호출할 경우 호출 지점에서 사용할 형식을 제공할 수 있습니다.
MyClass obj = new MyClass();
obj.MyMethod<int>(3);
즉, C# 컴파일러는 메서드가 호출되면 전달된 매개 변수의 형식을 기준으로 올바른 형식을 자동으로 유추할 수 있으며, 형식 지정을 전부
생략할 수도 있습니다.
MyClass obj = new MyClass();
obj.MyMethod(3);
이 기능을 generic 형식 유추라고 합니다. 컴파일러가 반환된 값의 형식만을 기준으로 형식을 유추할 수는 없습니다.
public class MyClass
{
public T MyMethod<T>()
{}
}
MyClass obj = new MyClass();
int number = obj.MyMethod();//컴파일되지 않습니다.
메서드는 자체 generic 형식 매개 변수를 정의할 때 해당 형식에 대한 제약 조건도 정의할 수 있습니다.
public class MyClass
{
public void SomeMethod<T>(T t) where T : IComparable<T>
{...}
}
그러나 클래스 수준 generic 형식 매개 변수에 메서드 수준 제약 조건을 제공할 수는 없습니다. 클래스 수준 generic 형식 매개
변수의 모든 제약 조건은 클래스 범위에서 정의되어야 합니다.
generic 형식 매개 변수를 정의하는 가상 메서드를 다시 정의할 경우 하위 클래스 메서드는 메서드별 generic 형식 매개 변수를
다시 정의해야 합니다.
public class BaseClass
{
public virtual void SomeMethod<T>(T t)
{...}
}
public class SubClass : BaseClass
{
public override void SomeMethod<T>(T t)
{...}
}
하위 클래스 구현에서는 기본 메서드 수준에 나타나는 모든 제약 조건을 반복해야 합니다.
public class BaseClass
{
public virtual void SomeMethod<T>(T t) where T : new()
{...}
}
public class SubClass : BaseClass
{
public override void SomeMethod<T>(T t) where T : new()
{...}
}
메서드를 다시 정의해도 기본 메서드에 나타나지 않는 새 제약 조건은 정의할 수 없습니다.
또한 하위 클래스 메서드가 가상 메서드의 기본 클래스 구현을 호출하는 경우 generic 기본 메서드 형식 매개 변수 대신 사용할 형식을
지정해야 합니다. 직접 명시적으로 지정하거나 가능한 경우 형식 유추를 사용할 수 있습니다.
public class BaseClass
{
public virtual void SomeMethod<T>(T t)
{...}
}
public class SubClass : BaseClass
{
public override void SomeMethod<T>(T t)
{
base.SomeMethod<T>(t);
base.SomeMethod(t);
}
}
generic 정적 메서드
C#에서는 generic 형식 매개 변수를 사용하는 정적 메서드를 정의할 수 있습니다. 그러나 이러한 정적 메서드를 호출할 경우 이
예제에서와 같이 호출 지점에서 포함하는 클래스에 대한 구체적인 형식을 제공해야 합니다.
public class MyClass<T>
{
public static T SomeMethod(T t)
{...}
}
int number = MyClass<int>.SomeMethod(3);
정적 메서드는 인스턴스 메서드와 마찬가지로 메서드별 generic 형식 매개 변수 및 제약 조건을 정의할 수 있습니다. 이러한 메서드를
호출할 경우 호출 지점에서 메서드별 형식을 다음과 같이 명시적으로 제공해야 합니다.
public class MyClass<T>
{
public static T SomeMethod<X>(T t,X x)
{..}
}
int number = MyClass<int>.SomeMethod<string>(3,"AAA");
또는 가능한 경우 형식 유추를 사용할 수 있습니다.
int number = MyClass<int>.SomeMethod(3,"AAA");
generic 정적 메서드는 클래스 수준에서 사용 중인 generic 형식 매개 변수에 적용되는 모든 제약 조건을 따릅니다.
인스턴스 메서드와 마찬가지로 정적 메서드가 정의한 generic 형식 매개 변수에 제약 조건을 제공할 수 있습니다.
public class MyClass
{
public static T SomeMethod<T>(T t) where T : IComparable<T>
{...}
}
C#의 연산자는 단지 정적 메서드일 뿐이며 C#에서는 generic 형식에 연산자를 오버로드할 수 있습니다. 코드 블록 3의
generic LinkedList가 + 연산자를 제공하여 연결 리스트를 연결했다고 가정하십시오. + 연산자를 사용하여 다음과 같이
적절한 코드를 작성할 수 있습니다.
LinkedList<int,string> list1 = new LinkedList<int,string>();
LinkedList<int,string> list2 = new LinkedList<int,string>();
...
LinkedList<int,string> list3 = list1+list2;
코드 블록 7은 LinkedList 클래스에서 generic + 연산자의 구현을 보여 줍니다. 연산자는 새
generic 형식 매개 변수를 정의할 수 없습니다.
코드 블록 7. generic 연산자 구현
public class LinkedList<K,T>
{
public static LinkedList<K,T> operator+(LinkedList<K,T> lhs,
LinkedList<K,T> rhs)
{
return concatenate(lhs,rhs);
}
static LinkedList<K,T> concatenate(LinkedList<K,T> list1,
LinkedList<K,T> list2)
{
LinkedList<K,T> newList = new LinkedList<K,T>();
Node<K,T> current;
current = list1.m_Head;
while(current != null)
{
newList.AddHead(current.Key,current.Item);
current = current.NextNode;
}
current = list2.m_Head;
while(current != null)
{
newList.AddHead(current.Key,current.Item);
current = current.NextNode;
}
return newList;
}
//LinkedList의 나머지 부분
}
generic 위임
클래스에 정의된 위임은 해당 클래스의 generic 형식 매개 변수를 활용할 수 있습니다. 다음 예를 살펴봅시다.
public class MyClass<T>
{
public delegate void GenericDelegate(T t);
public void SomeMethod(T t)
{...}
}
포함하는 클래스의 형식을 지정할 경우 위임에도 영향을 미칩니다.
MyClass<int> obj = new MyClass<int>();
MyClass<int>.GenericDelegate del;
del = new MyClass<int>.GenericDelegate(obj.SomeMethod);
del(3);
C# 2.0에서는 메서드 참조를 위임 변수에 직접 할당할 수 있습니다.
MyClass<int> obj = new MyClass<int>();
MyClass<int>.GenericDelegate del;
del = obj.SomeMethod;
이 기능을 위임 유추라고 합니다. 컴파일러는 지정된 이름을 기준으로 대상 개체에 메서드가 있는지 찾고 메서드의 서명 일치를 확인하여 할당된
위임의 형식을 유출할 수 있습니다. 그런 다음 컴파일러는 유추한 인수 형식(generic 형식 매개 변수 대신 올바른 형식 포함)의 새 위임을
만들어 유추된 위임에 할당할 수 있습니다.
클래스, 구조체 및 메서드와 마찬가지로 위임도 generic 형식 매개 변수를 정의할 수 있습니다.
public class MyClass<T>
{
public delegate void GenericDelegate<X>(T t,X x);
}
클래스 범위 외부에 정의된 위임은 generic 형식 매개 변수를 사용할 수 있습니다. 이 경우 위임을 선언하고 인스턴스화할 때 위임에
대한 특정 형식을 제공해야 합니다.
public delegate void GenericDelegate<T>(T t);
public class MyClass
{
public void SomeMethod(int number)
{...}
}
MyClass obj = new MyClass();
GenericDelegate<int> del;
del = new GenericDelegate<int>(obj.SomeMethod);
del(3);
또는 위임을 할당할 때 위임 유추를 사용할 수 있습니다.
MyClass obj = new MyClass();
GenericDelegate<int> del;
del = obj.SomeMethod;
기본적으로 위임은 generic 형식 매개 변수와 함께 사용될 제약 조건을 정의할 수 있습니다.
public delegate void MyDelegate<T>(T t) where T : IComparable<T>;
위임 수준 제약 조건은 형식 또는 메서드 범위에 있는 다른 모든 제약 조건과 마찬가지로 위임 변수를 선언하고 위임 개체를 인스턴스화할 때
사용하는 쪽에서만 적용됩니다.
generic 위임은 이벤트의 경우 특히 유용합니다. 문자 그대로, 필요한 generic 형식 매개 변수의 수에 의해서만 구분되는
generic 위임의 제한된 집합을 정의하고 이러한 위임을 이벤트 처리 작업에서 필요한 모든 곳에 사용할 수 있습니다. 코드 블록
8은 generic 위임 및 generic 이벤트 처리 메서드의 사용을 보여 줍니다.
코드 블록 8. generic 이벤트 처리
public delegate void GenericEventHandler<SenderType,ArgsType>(SenderType sender,
ArgsType args);
public class MyPublisher
{
public event GenericEventHandler<MyPublisher,EventArgs> MyEvent;
public void FireEvent()
{
MyEvent(this,EventArgs.Empty);
}
}
public class MySubscriber<ArgsType> //선택적: 특정 형식일 수 있습니다.
{
public void SomeMethod(MyPublisher sender,ArgsType args)
{...}
}
MyPublisher publisher = new MyPublisher();
MySubscriber<EventArgs> subs = new MySubscriber<EventArgs>();
publisher.MyEvent += subs.SomeMethod;
코드 블록 8은 generic sender 형식과 generic 형식 매개 변수를 받아들이는
GenericEventHandler라는 generic 위임을 사용합니다. 물론 매개 변수가 더 필요한 경우 generic 형식 매개
변수를 추가하기만 하면 되지만 GenericEventHandler를 generic이 아닌 .NET
EventHandler 뒤에 모델링하고자 합니다. EventHandler는 다음과 같이 정의되어 있습니다.
public void delegate EventHandler(object sender,EventArgs args);
EventHandler와 달리 GenericEventHandler는 형식이 안전합니다. 코드 블록
8에 나와 있듯이 일반 개체가 아니라 MyPublisher 형식의 개체만 발신자로 받아들이기 때문입니다.
generics 및 반사
.NET 2.0에서는 반사가 generic 형식 매개 변수를 지원하도록 확장되었습니다. 이제 Type 형식은 특정 형식 매개 변수가 있는
generic 형식(제한된(bounded) 형식) 또는 지정되지 않은(제한되지 않은(unbounded)) 형식을 나타낼 수 있습니다. C#
1.1에서와 같이 typeof 연산자를 사용하거나 모든 형식이 지원하는 GetType() 메서드를 호출하여 모든 형식의 Type을
얻을 수 있습니다. 선택한 방법에 관계없이 둘 다 동일한 Type이 나옵니다. 예를 들어 다음 코드 예제에서는 type1이
type2와 동일합니다.
LinkedList<int,string> list = new LinkedList<int,string>();
Type type1 = typeof(LinkedList<int,string>);
Type type2 = list.GetType();
Debug.Assert(type1 == type2);
typeof 및 GetType() 모두 naked generic 형식 매개 변수에서 사용할 수 있습니다.
public class MyClass<T>
{
public void SomeMethod(T t)
{
Type type = typeof(T);
Debug.Assert(type == t.GetType());
}
}
Type에는 형식의 generic 측면에 대한 반사 정보를 제공하도록 만들어진 새로운 메서드와 속성이 있습니다. 코드 블록
9는 새로운 메서드를 보여 줍니다.
코드 블록 9. Type의 generic 반사 멤버
public abstract class Type : //기본 형식입니다.
{
public int GenericParameterPosition{virtual get;}
public bool HasGenericParameters{get;}
public bool HasUnboundGenericParameters{virtual get;}
public bool IsGenericParameter{virtual get;}
public bool IsGenericTypeDefinition{virtual get;}
public virtual Type BindGenericParameters(Type[] typeArgs);
public virtual Type[] GetGenericParameters();
public virtual Type GetGenericTypeDefinition();
//멤버의 나머지 부분
}
이 새 멤버 중에서 가장 유용한 것은 HasGenericParameters 및
HasUnboundGenericParameters 속성과 GetGenericParameters() 및
GetGenericTypeDefinition() 메서드입니다. Type의 나머지 새 멤버는 고급 시나리오 및 이 기사의 범위를
벗어나는 다소 난해한 시나리오를 위한 것입니다. 이름에서 나타나듯이 HasGenericParameters는 Type 개체가 나타내는
형식이 generic 형식 매개 변수를 사용할 경우 true로 설정됩니다. GetGenericParameters()는 사용되는
제한된 형식에 해당하는 Type의 배열을 반환합니다. GetGenericTypeDefinition()은 원본 형식의 generic
형태를 나타내는 Type을 반환합니다. HasUnboundGenericParameters는 지정되지 않은 generic 형식 매개
변수가 Type 개체에 있는 경우 true입니다. 또한 HasUnboundGenericParameters는 generic 형식에서
호출될 때 GetGenericTypeDefinition()에서 반환된 Type에서 true로 설정됩니다.
코드 블록 10은 이러한 새 Type 멤버를 사용하여 코드 블록 3의 LinkedList에 대한
generic 반사 정보를 얻는 방법을 보여 줍니다.
코드 블록 10. generic 반사에 Type 사용
LinkedList<int,string> list = new LinkedList<int,string>();
Type boundedType = list.GetType();
Trace.WriteLine(boundedType.ToString());
//'LinkedList[System.Int32,System.String]'을 씁니다.
Debug.Assert(boundedType.HasGenericParameters);
Type[] parameters = boundedType.GetGenericParameters();
Debug.Assert(parameters.Length == 2);
Debug.Assert(parameters[0] == typeof(int));
Debug.Assert(parameters[1] == typeof(string));
Type unboundedType = boundedType.GetGenericTypeDefinition();
Debug.Assert(unboundedType.HasUnboundGenericParameters);
Trace.WriteLine(unboundedType.ToString());
//'LinkedList[K,T]'를 씁니다.
코드 블록 10에 나와 있듯이 Type은 제한된 매개 변수가 있는 generic 형식(코드 블록 10의
boundedType) 또는 제한되지 않은 매개 변수가 있는 generic 형식(코드 블록 10의
unboundedType)을 나타낼 수 있습니다.
Type과 유사하게 MethodInfo 및 해당 기본 클래스 MethodBase에는 generic 메서드 정보를
반사하는 새 멤버가 있습니다.
C# 1.1에서와 마찬가지로 MethodInfo 및 기타 다수의 옵션을 사용하여 런타임에 바인딩을 호출할 수 있습니다. 그러나
런타임에 바인딩에 대해 전달하는 매개 변수의 형식은 generic 형식 매개 변수 대신 사용되는 제한된 형식(있을 경우)과 일치해야 합니다.
LinkedList<int,string> list = new LinkedList<int,string>();
Type type = list.GetType();
MethodInfo methodInfo = type.GetMethod("AddHead");
object[] args = {1,"AAA"};
methodInfo.Invoke(list,args);
특성 및 generics
특성을 정의할 때 열거 AttributeTargets의 새 GenericParameter 값을 사용하여 특성이
generic 형식 매개 변수를 대상으로 하도록 컴파일러에 지정할 수 있습니다.
[AttributeUsage(AttributeTargets.GenericParameter)]
public class SomeAttribute : Attribute
{...}
C# 2.0에서는 generic 특성을 정의할 수 없습니다.
//다음은 컴파일되지 않습니다.
public class SomeAttribute<T> : Attribute
{...}
그러나 내부적으로 특성 클래스는 generic 형식을 사용하여 generics를 활용하거나 도우미 generic 메서드를 다른 형식과
마찬가지로 정의할 수 있습니다.
public class SomeAttribute : Attribute
{
void SomeMethod<T>(T t)
{...}
LinkedList<int,string> m_List = new LinkedList<int,string>();
}
generics 및 .NET Framework
.NET에서 C# 자체를 제외한 다른 일부 영역에서는 generics를 어떻게 활용하고 generics와 어떻게 상호 작용하는지 살펴보면서
이 기사를 마치겠습니다.
generic 컬렉션
System.Collections의 데이터 구조는 모두 개체 기반이므로 이 기사의 첫 부분에서 설명한 두 가지 문제, 즉 낮은 성능과 형식
안전성 부족의 문제가 계속해서 나타납니다. .NET 2.0에서는 System.Collections.Generics 네임스페이스에 새로운
generic 컬렉션 집합을 사용합니다. 예를 들어 generic Stack<T> 및 generic
Queue<T> 클래스가 있습니다. Dictionary<K,T> 데이터 구조는 generic이
아닌 HashTable과 동등하며 SortedList와 다소 비슷한
SortedDictionary<K,T> 클래스도 있습니다. List<T> 클래스는 generic이
아닌 ArrayList와 유사합니다. 표 1은 System.Collections.Generics의 새로운 형식을
System.Collections의 형식에 대응시킨 것입니다.
표 1. System.Collections.Generics를 System.Collections에
대응
| System.Collections.Generics |
System.Collections |
| Comparer<T> |
Comparer |
| Dictionary<K,T> |
HashTable |
| List<T> |
ArrayList |
| Queue<T> |
Queue |
| SortedDictionary<K,T> |
SortedList |
| Stack<T> |
Stack |
| ICollection<T> |
ICollection |
| IComparable<T> |
System.IComparable |
| IComparer<T> |
IComparer |
| IDictionary<K,T> |
IDictionary |
| IEnumerable<T> |
IEnumerable |
| IEnumerator<T> |
IEnumerator |
| IKeyComparer<T> |
IKeyComparer |
| IList<T> |
IList |
System.Collections.Generics에 있는 모든 generic 컬렉션은 다음과 같이 정의된 generic
IEnumerable<T> 인터페이스도 구현합니다.
public interface IEnumerable<T>
{
IEnumerator<T> GetEnumerator();
}
public interface IEnumerator<T> : IDisposable
{
T Current{get;}
bool MoveNext();
}
요약하자면 IEnumerable<T>는 컬렉션에서 추상적 반복에 사용되는
IEnumerator<T> iterator 인터페이스에 액세스할 수 있도록 합니다. 모든 컬렉션은 내포된 구조체에서
IEnumerable<T>를 구현하고, 내포된 구조체에서 generic 형식 매개 변수 T는 컬렉션이 저장하는
형식입니다.
관심이 가는 부분은 사전 컬렉션이 iterator를 정의하는 방법입니다. 사전은 실제로 하나가 아닌 두 가지 generic 매개 변수
형식(키 및 값)의 컬렉션입니다. System.Collection.Generics는 다음과 같이 정의된
KeyValuePair<K,V>라는 generic 구조체를 제공합니다.
struct KeyValuePair<K,V>
{
public KeyValuePair(K key,V value);
public K Key(get;set;)
public V Value(get;set;)
}
KeyValuePair<K,V>는 단순히 generic 키와 generic 값의 쌍을 저장할 뿐이며, 그럼으로써 실제로 새로운
generic 형식을 정의합니다. 이 새 형식은 사전에서 컬렉션으로 관리되며 IEnumerable<T>를 구현하는 데
사용됩니다. Dictionary 클래스는 generic KeyValuePair<K,V> 구조를
IEnumerable<T> 및 ICollection<T>의 항목 형식으로 지정합니다.
public class Dictionary<K,T> : IEnumerable<KeyValuePair<K,T>>,
ICollection<KeyValuePair<K,T>>,
//추가 인터페이스
{...}
KeyValuePair<K,V>에 사용되는 키 및 값 형식 매개 변수는 물론 사전 자체의 generic 키 및 값 형식 매개
변수입니다. 이 기술을 복합 generics라고 합니다.
키 및 값 쌍을 사용하는 사용자 고유의 generic 데이터 구조에서 복합 generics를 확실히 활용할 수 있습니다. 다음 예를
살펴봅시다.
public class LinkedList<K,T> : IEnumerable<KeyValuePair<K,T>> where K : IComparable<K>
{...}
serialization 및 generics
.NET에서는 serializable generic 형식을 사용할 수 있습니다.
[Serializable]
public class MyClass<T>
{...}
형식을 serialize할 때 .NET은 개체 멤버의 상태 외에도 개체 및 그 형식에 대한 메타데이터를 유지합니다. serializable
형식이 generic이고 제한된 형식을 포함하는 경우 제한된 형식에 대한 형식 정보도 generic 형식에 대한 메타데이터에 포함됩니다. 따라서
특정 인수 형식이 있는 generic 형식의 각 순열은 고유한 형식으로 간주됩니다. 예를 들어 개체 형식
MyClass<int>를 serialize할 수는 없지만 MyClass<string> 형식의
개체로 deserialize할 수는 있습니다. generic 형식의 인스턴스를 serialize하는 것은 generic이 아닌 형식을
serialize하는 것과 다르지 않습니다. 그러나 해당 형식을 deserialize할 경우에는 일치하는 특정 형식으로 변수를 선언하고
deserialize로부터 반환된 개체를 다운 캐스팅할 때 해당 형식을 다시 지정해야 합니다. 코드 블록 11은 generic
형식의 serialization 및 deserialization을 보여 줍니다.
코드 블록 11. generic 형식의 클라이언트 쪽 serialization
[Serializable]
public class MyClass<T>
{...}
MyClass<int> obj1 = new MyClass<int>();
IFormatter formatter = new BinaryFormatter();
Stream stream = new FileStream("obj.bin",FileMode.Create,FileAccess.ReadWrite);
formatter.Serialize(stream,obj1);
stream.Seek(0,SeekOrigin.Begin);
MyClass<int> obj2;
obj2 = (MyClass<int>)formatter.Deserialize(stream);
stream.Close();
사용자 지정 serialization을 제공하는 경우 deserialization 동안 값을 얻을 수도 있는
SerializationInfo라는 속성 모음에 값을 추가해야 합니다. serialization에 사용된
SerializationInfo를 제공하는 단일 메서드 GetObjectData()가 있는
ISerializable 인터페이스를 구현하십시오. 또한 개체 상태를 가져올 때 사용하는
SerializationInfo를 받아들이는 특수 생성자를 구현해야 합니다.
SerializationInfo는 필드 값을 가져오거나 추가할 수 있는 메서드를 제공합니다. 각 필드는 문자열로 식별됩니다.
SerializationInfo에는 int 및 string과 같은 대부분의 CLR 기본 형식에 대해 형식이 안전한 메서드가
있습니다.
public sealed class SerializationInfo
{
public void AddValue(string name, int value);
public int GetInt32(string name);
//기타 메서드 및 속성
}
generic 형식에 사용자 지정 serialization을 제공할 때의 문제는 추가 메서드 또는 가져오기 메서드 중에서 어느 것을
사용해야 할지 모른다는 것입니다. 이 문제를 해결하기 위해 SerializationInfo는 개체 및 그 형식을 추가하거나 가져올
수 있는 메서드를 제공합니다.
public void AddValue(string name, object value, Type type);
public object GetValue(string name,Type type);
참고 이 메서드는 .NET 1.1에서도 사용할 수 있습니다.
AddValue()를 사용할 경우 generic 매개 변수 형식의 형식을 가져옵니다. GetValue()를 호출할
경우에는 GetValue()가 개체를 반환하므로 generic 매개 변수 형식으로의 캐스트를 사용합니다. 코드
블록 12는 이러한 AddValue() 및 GetValue() 메서드의 사용을 보여 줍니다.
코드 블록 12. generic 클래스의 사용자 지정 serialization
[Serializable]
public class MyClass<T> : ISerializable
{
public MyClass()
{}
public void GetObjectData(SerializationInfo info,StreamingContext ctx)
{
info.AddValue("m_T",m_T,typeof(T));
}
private MyClass(SerializationInfo info,StreamingContext context)
{
m_T = (T)info.GetValue("m_T",typeof(T));
}
T m_T;
}
그러나 generic 형식에 좀 더 효율적이고 안전하게 사용자 지정 serialization을 제공할 수 있는 방법이 있습니다. 코드
블록 13은 generic AddValue() 및 GetValue() 메서드를 노출하는
GenericSerializationInfo 유틸리티 클래스를 나타냅니다. 일반 SerializationInfo를
캡슐화함으로써 GenericSerializationInfo는 형식 검색 및 명시적 캐스팅으로부터 클라이언트 코드를 보호합니다.
코드 블록 13. GenericSerializationInfo 유틸리티 클래스
public class GenericSerializationInfo
{
SerializationInfo m_SerializationInfo;
public GenericSerializationInfo(SerializationInfo info)
{
m_SerializationInfo = info;
}
public void AddValue<T>(string name,T value)
{
m_SerializationInfo.AddValue(name,value,value.GetType());
}
public T GetValue<T>(string name)
{
object obj = m_SerializationInfo.GetValue(name,typeof(T));
return (T)obj;
}
}
코드 블록 14는 GenericSerializationInfo를 사용한다는 것만 제외하고는 코드 블록
12와 동일한 사용자 지정 serialization 코드를 보여 줍니다. AddValue() 호출에서 형식 유추가 사용되는
것을 볼 수 있습니다.
코드 블록 14. GenericSerializationInfo 사용
[Serializable]
public class MyClass<T> : ISerializable
{
public MyClass()
{}
public void GetObjectData(SerializationInfo info,StreamingContext ctx)
{
GenericSerializationInfo genericInfo = new GenericSerializationInfo(info);
genericInfo.AddValue("m_T",m_T); //형식 유추 사용
}
private MyClass(SerializationInfo info,StreamingContext context)
{
GenericSerializationInfo genericInfo = new GenericSerializationInfo(info);
m_T = genericInfo.GetValue<T>("m_T");
}
T m_T;
}
generic이 아닌 클래스 멤버에서도 GenericSerializationInfo를 좀 더 쉬운 사용자 지정
serialization 구현 방법으로 사용할 수 있습니다. 예를 들어 코드 블록 14의 MyClass에
m_Name이라는 형식 문자열의 클래스 멤버가 있으면 다음과 같이 코드를 작성할 수 있습니다.
genericInfo.AddValue("m_Name",m_Name);
및
m_Name = genericInfo.GetValue<string>("m_Name");
generics 및 원격
generics를 활용하는 원격 클래스를 정의하고 배포할 수 있으며, 프로그래밍 방식의 구성 또는 관리 구성을 사용할 수 있습니다.
generics를 사용하는 MyServer 클래스가 MarshalByRefObject에서 파생된다고 가정해 보십시오.
public class MyServer<T> : MarshalByRefObject
{...}
관리 형식 등록을 사용하는 경우 generic 형식 매개 변수 대신 사용할 정확한 형식을 지정해야 합니다. 언어 중립적인 방법으로 형식의
이름을 지정하고 정규화된 네임스페이스를 제공해야 합니다. 예를 들어 ServerAssembly 어셈블리의
RemoteServer 네임스페이스에 정의되어 있는 MyServer 클래스를 클라이언트 활성화 모드에서 generic
형식 매개 변수 T 대신 정수와 함께 사용하려고 합니다. 이 경우 구성 파일에서 필요한 클라이언트 쪽 형식 등록 항목은 다음과 같습니다.
<client url="...some url goes here...">
<activated type="RemoteServer.MyServer[[System.Int32]],ServerAssembly"/>
</client>
구성 파일에서 대응하는 호스트 쪽 형식 등록 항목은 다음과 같습니다.
<service>
<activated type="RemoteServer.MyServer[[System.Int32]],ServerAssembly"/>
</service>
이중 대괄호는 복수 형식을 지정하는 데 사용됩니다. 다음 예를 살펴봅시다.
LinkedList[[System.Int32],[System.String]]
프로그래밍 방식 구성을 사용하는 경우 generic 형식 매개 변수 대신 특정 형식을 제공해야 하는 원격 개체의 형식을 정의할 때를
제외하고는 C# 1.1과 비슷한 활성화 모드 및 형식 등록을 구성합니다. 예를 들어 호스트 쪽 활성화 모드 및 형식 등록에 대해 다음과 같이
씁니다.
Type serverType = typeof(MyServer<int>);
RemotingConfiguration.RegisterActivatedServiceType(serverType);
클라이언트 쪽 형식 활성화 모드 및 위치 등록에 대해서는 다음과 같이 씁니다.
Type serverType = typeof(MyServer<int>);
string url = ...; //일부 url 초기화
RemotingConfiguration.RegisterWellKnownClientType(serverType,url);
원격 서버를 인스턴스화하는 경우 로컬 generic 형식을 사용할 때처럼 특정 형식을 제공하기만 하면 됩니다.
MyServer<int> obj;
obj = new MyServer<int>();
//obj 사용
클라이언트는 새 메서드를 사용하는 대신 Activator 클래스의 메서드를 선택적으로 사용하여 원격 개체에 연결할 수
있습니다. Activator.GetObject()를 사용할 때는 사용할 특정 형식을 제공해야 하며 반환된 개체를 명시적으로 캐스팅할
때는 특정 형식을 제공해야 합니다.
string url = ...; //일부 url 초기화
Type serverType = typeof(MyServer<int>);
MyServer<int> obj;
obj = (MyServer<int>)Activator.GetObject(serverType,url);
//obj 사용
Activator.CreateInstance() 메서드에는 수많은 오버로드 버전이 있습니다. 그 중 일부 버전을 generic
형식에 사용할 수 있습니다.
Type serverType = typeof(MyServer<int>);
MyServer<int> obj;
obj = (MyServer<int>)Activator.CreateInstance(serverType);
//obj 사용
그러나 generic 형식에는 다음과 같이 문자열 형식을 받아들이고 ObjectHandle을 반환하는
CreateInstance() 및 CreateInstanceFrom()의 버전을 사용할 수 없습니다.
public static ObjectHandle CreateInstance(string assemblyName,string typeName);
Activator는 generics를 고려하지 않고 만들었기 때문에 개체로부터의 명시적인 캐스트로 인해 형식이 완전히
안전하지는 않습니다. 코드 블록 15에서와 같이 GenericActivator 클래스를 정의하여 이를 보완할 수
있습니다.
코드 블록 15. GenericActivator
public class GenericActivator
{
public static T CreateInstance<T>()
{
return (T)Activator.CreateInstance(typeof(T));
}
public static T GetObject<T>(string url)
{
return (T)Activator.GetObject(typeof(T),url);
}
}
GenericActivator는 generic 정적 메서드를 사용하여 Activator의 가장 유용한 메서드를
노출합니다. GenericActivator를 Activator 대신 사용하여 generic 형식 및 generic이
아닌 형식을 활성화할 수 있습니다. 예를 들어 GetObject()를 사용합니다.
public class MyServer : MarshalByRefObject
{...}
public class MyGenericServer<T> : MarshalByRefObject
{...}
string url = ...; //일부 url 초기화
MyServer obj1 = GenericActivator.GetObject<MyServer>(url);
MyGenericServer obj2 = GenericActivator.GetObject<MyServer<int>>(url);
또는 CreateInstance()를 사용합니다.
MyServer obj = GenericActivator.CreateInstance<MyServer>();
generics에서 불가능한 작업
.NET 2.0에서는 generic 웹 서비스, 즉, generic 형식 매개 변수를 사용하는 웹 메서드를 정의할 수 없습니다.
generic 서비스를 지원하는 웹 서비스 표준이 없기 때문입니다.
서비스되는 구성 요소에서도 generic 형식을 사용할 수 없습니다. 서비스되는 구성 요소에 필요한 COM 표시 유형 요구 사항을
generics가 충족하지 못하기 때문입니다. COM 또는 COM+에서 C++ 템플릿을 사용할 수 없는 것과 마찬가지입니다.
결론
C# generics는 새로운 주요 개발 방법으로서 적절하고 읽기 쉬운 구문을 사용하여 성능, 형식 안전성 및 품질을 향상시키고, 반복적인
프로그래밍 작업을 줄이고, 전체 프로그래밍 모델을 단순화합니다. C# generics는 C++ 템플릿을 기반으로 하고 있지만 C#는 코드
비대화를 없애고 컴파일 시 안전성 및 지원을 제공함으로써 generics의 수준을 한 차원 높였습니다. C#는 2단계 컴파일, 메타데이터, 제약
조건 및 generic 메서드와 같은 혁신적인 개념을 활용합니다. C#의 향후 버전이 generics를 지속적으로 발전시켜 새로운 기능을
추가하고 generics를 데이터 액세스 또는 지역화 등 .NET Framework의 다른 영역까지 확장할 것은 분명합니다.
Juval Lowy는 소프트웨어 개발자이자 컨설팅 및 교육 회사인 IDesign의 사장입니다. Juval은 실리콘 밸리의
Microsoft 지역 담당으로서 Microsoft가 .NET을 업계에 보급하는 데 협력하고 있습니다. 최근의 저서는 Programming
.NET Components(O'Reilly, 2003)입니다. 이 책은 구성 요소 지향 프로그램 및 디자인, 관련 시스템 문제에 대해 다루고
있습니다. Juval은 .NET의 향후 버전에 대한 Microsoft 내부 디자인 검토에 참여하고 있습니다. Microsoft에서는 Juval을
소프트웨어 업계의 전설적인 존재이자 세계 최고의 .NET 전문가 및 업계 선도자 중 한 명으로 인정하고 있습니다. http://www.idesign.net/ 에서 Juval을 만나실 수 있습니다.
출처:http://www.microsoft.com/korea

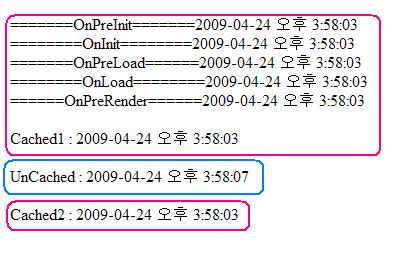
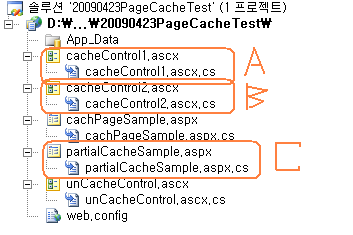

 정
상적인 Page의 Event Flow : PreInit -> Init -> InitComplete ->
PreLoad -> Load -> LoadComplete -> PreRender -> Render
정
상적인 Page의 Event Flow : PreInit -> Init -> InitComplete ->
PreLoad -> Load -> LoadComplete -> PreRender -> Render 


